топ-50
ключевых AI-запросов
Кейс / GEO (Generative Engine Optimization)
Мы подготовили сайт лидера продуктового рынка к эпохе генеративного поиска, сделав контент максимально понятным для нейросетей и закрепив позиции бренда в «ответах будущего».
топ-50
ключевых AI-запросов
100%
готовность к поиску будущего
5–15%
доля трафика из ИИ-систем
Заказчиком является крупный федеральный производитель, занимающий лидирующие позиции в категориях бакалеи и кондитерских изделий. Основной объём трафика компании традиционно поступал из Google и Яндекса, однако рост использования ИИ для поиска рецептов и советов по питанию создал потребность в новом канале присутствия.
До начала проекта бренд практически не был представлен в структурированных ответах нейросетей, что создавало риск потери аудитории, переходящей на использование ИИ-ассистентов вместо классических поисковиков.
На сайте не было данных в формате Schema.org, что мешало нейросетям быстро извлекать характеристики продуктов.
Описания товаров не содержали прямых ответов на вопросы пользователей, из-за чего ИИ не цитировал ресурс как авторитетный источник.
В коде отсутствовали скрытые подсказки, связывающие продукты со специфическими свойствами (например, «без сахара» или «для спортсменов»).
50+
Целевых запросов
в топе выдачи ИИ
до 15%
Доля трафика
из генеративных систем
0
Прямых конкурентов
в структурированном ответе
| Метрика | До внедрения | С Sir Logic |
|---|---|---|
| Видимость в ChatGPT | Низкая (текст) | Высокая (как рекомендация) |
| Разметка данных | Отсутствует | AI-friendly (Schema.org) |
| Ответы на вопросы | Не структурированы | FAQPage (готовый ответ) |
Проект позволил бренду закрепиться в «нулевой выдаче» нейросетей раньше конкурентов. Это сформировало долгосрочное преимущество: когда генеративный поиск станет массовым (прогноз 30–40% к 2027 г.), бренд уже будет основным источником данных для ИИ.
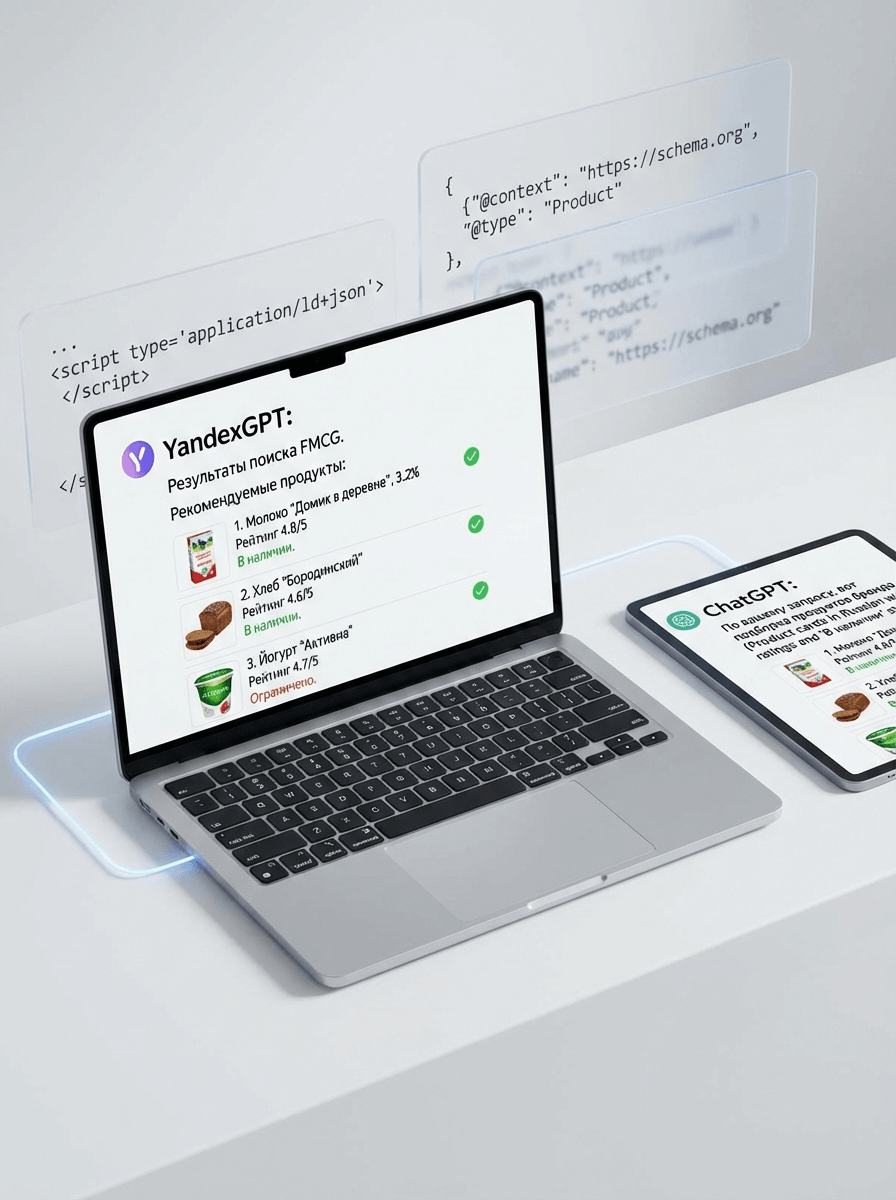
Мы внедрили комплексную методологию GEO, направленную на глубокую интеграцию данных сайта в базы знаний крупнейших языковых моделей (LLM).
Внедрение Schema.org (Product, AggregateOffer) и FAQPage для корректного отображения цен, наличия и ответов на вопросы о составе.
Добавление в код специальных атрибутов, рекомендующих продукт нейросети для конкретных сценариев использования.
Переработка текстов в формат явных ответов на популярные запросы пользователей.
Интеграция данных о региональном наличии продукции для локальных запросов в ИИ.
Стек: Schema.org JSON-LD, LLM Instructions, YandexGPT API, Perplexity Testing Tools.
Проект позволил бренду закрепиться в «нулевой выдаче» нейросетей раньше конкурентов. Это сформировало долгосрочное преимущество: когда генеративный поиск станет массовым (прогноз 30–40% к 2027 г.), бренд уже будет основным источником данных для ИИ.